Study Bay Coursework Assignment Writing Help
Efficiency Analysis of Lazy, Decision Tree classifier and Multilayer Perceptron on Visitors Accident Assessment
Summary. Visitors and street accident are a giant situation in each nation. Street accident affect on many issues reminiscent of property injury, completely different harm stage in addition to a considerable amount of loss of life. Information science has such functionality to help us to investigate various factors behind site visitors and street accident reminiscent of climate, street, time and many others. On this paper, we proposed completely different clustering and classification methods to investigate knowledge. We applied completely different classification methods reminiscent of Decision Tree, Lazy classifier, and Multilayer perceptron classifier to categorise dataset primarily based on casualty class in addition to clustering methods that are k-means and Hierarchical clustering methods to cluster dataset. Firstly we analyzed dataset by utilizing these classifiers and we achieved accuracy at some stage and later, we utilized clustering methods and then utilized classification methods on that clustered knowledge. Our accuracy stage elevated at some stage by utilizing clustering methods on dataset in comparison with a dataset which was categorised with out clustering.
Key phrases: Decision tree, Lazy classifier, Multilayer perceptron, Ok-means, Hierarchical clustering
- INTRODUCTION
Visitors and street accident are one of many vital downside internationally. Diminishing accident ratio is best approach to enhance site visitors security. There are a lot of kind of analysis has been executed in lots of nations in site visitors accident Assessment by utilizing completely different kind of knowledge mining methods. Many researcher proposed their work with a purpose to cut back the accident ratio by figuring out threat components which significantly affect within the accident [1-5]. There are additionally completely different methods used to investigate site visitors accident however it’s said that knowledge mining approach is extra advance approach and proven higher outcomes as in comparison with statistical Assessment. Nevertheless, each strategies present considerable consequence which is useful to cut back accident ratio [6-13, 28, 29].
From the experimental viewpoint, largely research tried to seek out out the chance components which have an effect on the severity ranges. Amongst most of research defined that ingesting alcoholic beverage and driving influenced extra in accident [14]. It recognized that ingesting alcoholic beverage and driving significantly improve the accident ratio. There are numerous research which have centered on restraint gadgets like helmet, seat belts affect the severity stage of accident and if these gadgets would have been used to accident ratio had decreased at sure stage [15]. As well as, few research have centered on figuring out the group of drivers who’re largely concerned in accident. Aged drivers whose age are greater than 60 years, they’re recognized largely in street accident [16]. Many research supplied completely different stage of threat components which influenced extra in severity stage of accident.
Lee C [17] said that statistical approaches had been good possibility to investigate the relation between in varied threat components and accident. Though, Chen and Jovanis [18] recognized that there are some downside like massive contingency desk throughout analyzing huge dimensional dataset by utilizing statistical methods. In addition to statistical method even have their very own violation and assumption which might deliver some error outcomes [30-33]. Due to these limitation in statistical method, Information methods got here into existence to investigate knowledge of street accident. Information mining typically referred to as as data or knowledge discovery. That is set of methods to attain hidden info from great amount of knowledge. It’s proven that there are lots of implementation of knowledge mining in transportation system like pavement Assessment, roughness Assessment of street and street accident Assessment.
Information mining methods has been probably the most extensively used methods in area like agriculture, medical, transportation, enterprise, industries, engineering and many different scientific fields [21-23]. There are a lot of numerous knowledge mining methodologies reminiscent of classification, affiliation guidelines and clustering has been extensivally used for analyzing dataset of street accident [19-20]. Geurts Ok [24] analyzed dataset by utilizing affiliation rule mining to know the various factors that occurs at very excessive frequency street accident areas on Belgium street. Depaire [25] analyzed dataset of street accident in Belgium by utilizing completely different clustering methods and said that clustered primarily based knowledge can extract higher info as in contrast with out clustered knowledge. Kwon analyzed dataset by utilizing Decision Tree and NB classifiers to components which is affecting extra in street accident. Kashani [27] analyzed dataset by utilizing classification and regression algorithm to investigate accident ratio in Iran and achieved that there are components reminiscent of mistaken overtaking, not utilizing seat belts, and badly dashing affected the severity stage of accident.
- METHODOLOGY
This analysis work concentrate on casualty class primarily based classification of street accident. The paper describe the k-means and Hierarchical clustering methods for cluster Assessment. Furthermore, Decision Tree, Lazy classifier and Multilayer perceptron used on this paper to categorise the accident knowledge.
- Clustering Strategies
Hierarchical Clustering
Hierarchical clustering is also called HCS (Hierarchical cluster Assessment). It’s unsupervised clustering methods which try and make clusters hierarchy. It’s divided into two classes that are Divisive and Agglomerative clustering.
Divisive Clustering: On this clustering approach, we allocate the entire inspection to 1 cluster and later, partition that single cluster into two comparable clusters. Lastly, we proceed repeatedly on each cluster until there could be one cluster for each inspection.
Agglomerative technique: It’s backside up method. We allocate each inspection to their very own cluster. Later, consider the space between each clusters and then amalgamate probably the most two comparable clusters. Repeat steps second and third till there could possibly be one cluster left. The algorithm is given beneath
           X set A of objects a1, a2,………an
           Distance perform is d1 and d2
           For j=1 to n
          dj=
         finish for
         D= d1, d2,…..dn
        Y=n+1
        whereas D.measurement>1 do
-(dmin1, dmin2)=minimal distance (dj, dk) for all dj, dk in all D
-Delete dmin1 and dmin2 from D
-Add (dmin1, dmin2) to D
-Y=Y+1
         finish whereas
Ok-modes clustering
Clustering is an knowledge mining approach which use unsupervised studying, whose main goal is to categorize the info options into a definite kind of clusters in such a approach that options inside a gaggle are extra alike than the options in numerous clusters. Ok-means approach is an extensively used clustering approach for giant numerical knowledge Assessment. On this, the dataset is grouped into k-clusters. There are numerous clustering methods obtainable however the assortment of acceptable clustering algorithm depend on the character and kind of knowledge. Our main goal of this work is to distinguish the accident locations on their frequency prevalence. Let‘s assume thatX and Y is a matrix of m by n matrix of categorical knowledge. The easy closeness coordinating measure amongst X and Y is the amount of coordinating high quality estimations of the 2 values. The extra noteworthy the amount of matches is extra the comparability of two gadgets. Ok-modes algorithm might be defined as:
                            d (Xi,Yi)= 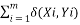                   —————–(1)
                  —————–(1)
               The place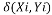
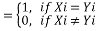 Â Â Â Â Â Â Â Â Â Â —————- (2)
          —————- (2)
- Classification Strategies
Lazy Classifier
Lazy classifier save the coaching situations and do no real work till classification time. Lazy classifier is a studying technique by which hypothesis previous the preparation info is postponed till a Question Assignment is made to the framework the place the framework tries to sum up the coaching knowledge earlier than getting queries. The primary benefit of using a lazy classification technique is that the target scope will probably be exacted regionally, for instance, within the k-nearest neighbor. Because the goal capability is approximated regionally for every Question Assignment to the framework, lazy classifier frameworks can concurrently maintain varied points and association successfully with adjustments within the situation area. The burdens with lazy classifier incorporate the in depth house necessity to retailer the overall getting ready dataset. For probably the most half boisterous getting ready info expands the case bolster pointlessly, in mild of the truth that no thought is made amid the preparation stage and one other detriment is that lazy classification methods are usually slower to evaluate, nevertheless that is joined with a faster getting ready stage.
Ok Star
The Ok star might be characterised as a method for cluster examination which basically goes for the partition of n notion into k-clusters, the place each notion has a location with the group to the closest imply. We are able to depict Ok star as an prevalence primarily based learner which makes use of entropy as a separation measure. The benefits are that it provides a predictable strategy to cope with remedy of real esteemed attributes, typical attributes and lacking attributes. Ok star is a fundamental, occasion primarily based classifier, like Ok Nearest Neighbor (Ok-NN). New knowledge occasion, x, are doled out to the category that occurs most each now and once more among the many ok closest info focuses, yj, the place j = 1, 2… ok. Entropic separation is then used to get better probably the most comparable events from the informational index. By technique for entropic take away as a metric has an a variety of benefits together with remedy of real esteemed qualities and lacking qualities. The Ok star perform might be ascertained as:
Ok*(yi, x)=-ln P*(yi, x)
The place P* is the probability of all transformational means from occasion x to y. It may be invaluable to grasp this because the probability that x will contact base at y by the use of an arbitrary stroll in IC spotlight house. It’ll carried out streamlining over the p.c mixing proportion parameter which is intently resembling Ok-NN ‘sphere of affect’, earlier than appraisal with different Machine Studying methods.
IBK (Ok – Nearest Neighbor)
It’s a k-closest neighbor classifier approach that make the most of the same separation metric. The amount of closest neighbors could also be illustrated unequivocally within the object editor or decided consequently using blow one cross-approval heart to a most level of confinement supplied by the predetermined esteem. IBK is the knearest-neighbor classifier. A type of divorce pursuit calculations could be used to quicken the errand of figuring out the closest neighbors. A direct inquiry is the default but promote resolution mix ball bushes, KD-trees, thus referred to as “cowl bushes”. The dissolution work used is a parameter of the inquiry technique. The remainder of the factor is alike one the premise of IBL-which known as Euclidean separation; completely different alternate options mix Chebyshev, Manhattan, and Minkowski separations. Forecasts larger than one neighbor could also be weighted by their distance from the take a look at prevalence and two distinctive equations are applied for altering over the space right into a weight. The amount of getting ready events saved by the classifier might be restricted by setting the window estimate selection. As new getting ready events are included, probably the most seasoned ones are segregated to maintain up the amount of getting ready instances at this measurement.
Decision Tree
Random resolution forests or random forest are a bundle studying methods for regression, classification and different duties, that carry out by constructing a legion of resolution bushes at coaching time and ensuing the category which might be the mode of the imply prediction (regression) or courses (classification) of the separate bushes. Random resolution forests good for resolution bushes’ routime of overfitting to their coaching set. In several calculations, the classification is executed recursively until every and each leaf is clear or pure, that’s the order of the info should be as impeccable as could be prudent. The purpose is dynamically hypothesis of a selection tree till it picks up the steadiness of adaptability and exactness. This method utilized the ‘Entropy’ that’s the computation of dysfunction knowledge. Right here Entropy 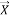 is measured by:
is measured by:
                                Entropy () = –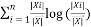
                                 Entropy (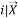 ) =
) = 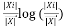
Therefore so complete acquire = Entropy () – Entropy ()
Right here the purpose is to extend the overall acquire by dividing complete entropy due to diverging arguments by worth i.
Multilayer Perceptron
An MLP could be noticed as a logistic regression classifier by which enter knowledge is firstly altered using a non-linear transformation. This alteration deal the enter dataset into house, and the place the place this flip into linearly separable. This layer as an intermediate layer is named a hidden layer. One hidden layer is sufficient to create MLPs.
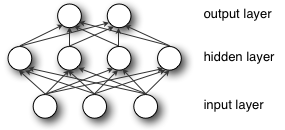
Formally, a single hidden layer Multilayer Perceptron (MLP) is a perform of f: YI→YO, the place I could be the enter measurement vector x and O is the dimensions of output vector f(x), such that, in matrix notation
                                               F(x) = g(θ(2)+W(2)(s(θ(1)+W(1)x)))
- DESCRIPTION OF DATASET
The site visitors accident knowledge is obtained from on-line knowledge supply for Leeds UK [8]. This knowledge set includes 13062 accident which occurred since final 5 years from 2011 to 2015. After fastidiously analyzed this knowledge, there are 11 attributes found for this examine. The dataset consist attributes that are Variety of automobiles, time, street floor, climate circumstances, lightening circumstances, casualty class, intercourse of casualty, age, kind of car, day and month and these attributes have completely different options like casualty class has driver, pedestrian, passenger in addition to similar with different attributes with having completely different options which was given in knowledge set. These knowledge are proven briefly in desk 2
- ACCURACY MEASUREMENT
The accuracy is outlined by completely different classifiers of supplied dataset and that’s achieved a share of dataset tuples which is assessed exactly by Help of various classifiers. The confusion matrix can be referred to as as error matrix which is simply structure desk that allows to visualise the habits of an algorithm. Right here complicated matrix offers additionally an vital function to attain the effectivity of various classifiers. There are two class labels given and every cell consist prediction by a classifier which comes into that cell.
Desk 1
|
Confusion Matrix |
||
|
                            Appropriate Labels |
||
|
Damaging |
Optimistic |
|
|
Damaging |
TN (True detrimental) |
FN (False detrimental) |
|
Optimistic |
FP (False constructive) |
TP (True constructive) |
Now, there are lots of components like Accuracy, sensitivity, specificity, error charge, precision, f-measures, recall and so on.
TPR (Accuracy or True Optimistic Fee) = 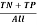
FPR (False Optimistic Fee) = 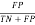
Precision = 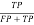
Sensitivity = 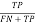
And there are additionally different components which might discover out to categorise the dataset appropriately.
- RESULTS AND DISCUSSION
Desk 2 describe all of the attributes obtainable within the street accident dataset. There are 11 attributes talked about and their code, values, complete and different components included. We divided complete accident worth on the premise of casualty class which is Driver, Passenger, and Pedestrian by the Helpance of SQL.
Desk 2
|
S.NO. |
Attribute |
Code |
Worth |
Whole |
       Casualty Class |
||
|
Driver |
Passenger |
Pedestrian |
|||||
|
1. |
No. of automobiles |
1 |
1 car |
3334 |
763 |
817 |
753 |
|
2 |
2 car |
7991 |
5676 |
2215 |
99 |
||
|
three+ |
>three car |
5214 |
1218 |
510 |
10 |
||
|
2. |
Time |
T1 |
[0-4] |
630 |
269 |
250 |
110 |
|
T2 |
[4-8] |
903 |
698 |
133 |
71 |
||
|
T3 |
[6-12] |
2720 |
1701 |
644 |
374 |
||
|
T4 |
[12-16] |
3342 |
1812 |
1027 |
502 |
||
|
T5 |
[16-20] |
3976 |
2387 |
990 |
598 |
||
|
T6 |
[20-24] |
1496 |
790 |
498 |
207 |
||
|
three. |
Street Floor |
OTR |
Different |
106 |
62 |
30 |
13 |
|
DR |
Dry |
9828 |
5687 |
2695 |
1445 |
||
|
WT |
Moist |
3063 |
1858 |
803 |
401 |
||
|
SNW |
Snow |
157 |
101 |
39 |
16 |
||
|
FLD |
Flood |
17 |
11 |
5 |
zero |
||
|
four. |
Lightening Situation |
DLGT |
Day Gentle |
9020 |
5422 |
2348 |
1249 |
|
NLGT |
No Gentle |
1446 |
858 |
389 |
198 |
||
|
SLGT |
Road Gentle |
2598 |
1377 |
805 |
415 |
||
|
5. |
Climate Situation |
CLR |
Clear |
11584 |
6770 |
3140 |
1666 |
|
FG |
Fog |
37 |
26 |
7 |
three |
||
|
SNY |
Snowy |
63 |
41 |
15 |
6 |
||
|
RNY |
Wet |
1276 |
751 |
350 |
174 |
||
|
6. |
Casualty Class |
DR |
Driver |
||||
|
PSG |
Passenger |
||||||
|
PDT |
Pedestrian |
||||||
|
7. |
Intercourse of Casualty |
M |
Male |
7758 |
5223 |
1460 |
1074 |
|
F |
Feminine |
5305 |
2434 |
2082 |
788 |
||
|
eight. |
Age |
Minor |
<18 years |
1976 |
454 |
855 |
667 |
|
Youth |
18-30 years |
4267 |
2646 |
1158 |
462 |
||
|
Grownup |
30-60 years |
4254 |
3152 |
742 |
359 |
||
|
Senior |
>60 years |
2567 |
1405 |
787 |
374 |
||
|
9. |
Sort of Automobile |
BS |
Bus |
842 |
52 |
687 |
102 |
|
CR |
Automotive |
9208 |
4959 |
2692 |
1556 |
||
|
GDV |
GoodsVehicle |
449 |
245 |
86 |
117 |
||
|
BCL |
Bicycle |
1512 |
1476 |
11 |
24 |
||
|
PTV |
PTWW |
977 |
876 |
48 |
52 |
||
|
OTR |
Different |
79 |
49 |
18 |
11 |
||
|
10. |
Day |
WKD |
Weekday |
9884 |
5980 |
2499 |
1404 |
|
WND |
Weekend |
3179 |
1677 |
1043 |
458 |
||
|
11. |
Month |
Q1 |
Jan-March |
3017 |
1731 |
803 |
482 |
|
Q2 |
April-June |
3220 |
1887 |
907 |
425 |
||
|
Q3 |
July-September |
3376 |
2021 |
948 |
406 |
||
|
This autumn |
Oct-December |
3452 |
2018 |
884 |
549 |
||
- Direct Classification Assessment
We utilized completely different approaches to categorise this bunch of dataset on the premise of casualty class. We used classifier that are Decision Tree, Lazy classifier and Multilayer perceptron. We attained some consequence to few stage as proven in desk three
Desk three
|
Classifiers |
Accuracy |
|
Lazy classifier(Ok-Star) |
67.7324% |
|
Lazy classifier (IBK) |
68.5634% |
|
Decision Tree |
70.7566% |
|
Multilayer perceptron |
69.3031% |
We achieved some outcomes to this given stage by utilizing these three approaches and then later we utilized completely different clustering methods that are Hierarchical clustering and Ok-modes.
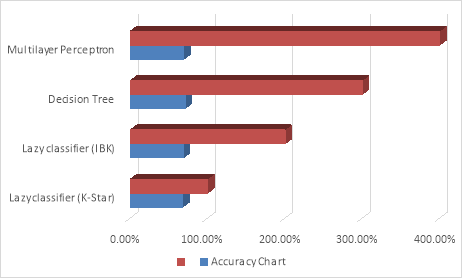
Determine 1Â Direct categorised Accuracy
- Assessment by utilizing clustering methods
On this Assessment, we utilized two clustering methods that are Hierarchical and Ok-modes methods, Later we divided dataset into 9 clusters. We achieved higher outcomes by utilizing Hierarchical as in comparison with Ok-modes methods.
Lazy Classifier Output
Ok Star: On this, our categorised consequence elevated from 67.7324 % to 82.352%. It’s sharp enchancment in consequence after clustering.
Desk four
|
TP Fee |
FP Fee |
Precision |
Recall |
F-Measure |
MCC |
ROC Space |
PRC Space |
Class |
|
zero.956 |
zero.320 |
zero.809 |
zero.956 |
zero.876 |
zero.679 |
zero.928 |
zero.947 |
Driver |
|
zero.529 |
zero.029 |
zero.873 |
zero.529 |
zero.659 |
zero.600 |
zero.917 |
zero.824 |
Passenger |
|
zero.839 |
zero.027 |
zero.837 |
zero.839 |
zero.838 |
zero.811 |
zero.981 |
zero.906 |
Pedestrian |
IBK: On this, our categorised consequence elevated from 68.5634% to 84.4729%. It’s sharp enchancment in consequence after clustering.
Desk 5
|
TP Fee |
FP Fee |
Precision |
Recall |
F-Measure |
MCC |
ROC Space |
PRC Space |
Class |
|
zero.945 |
zero.254 |
zero.840 |
zero.945 |
zero.890 |
zero.717 |
zero.950 |
zero.964 |
Driver |
|
zero.644 |
zero.048 |
zero.833 |
zero.644 |
zero.726 |
zero.651 |
zero.940 |
zero.867 |
Passenger |
|
zero.816 |
zero.zero18 |
zero.884 |
zero.816 |
zero.849 |
zero.826 |
zero.990 |
zero.946 |
Pedestrian |
Decision Tree Output
On this examine, we used Decision Tree classifier which improved the accuracy higher than ear
